
The Brainstorm question type
We introduced the Brainstorm question at the end of 2020, and have improved it since. To learn more about what the Brainstorm question is or how it works, read our blog post:
Simply ask a question that kicks off a discussion, and participants can submit up to three ideas. When the ideas are displayed on the shared screen, you can discuss and group similar topics before the participants individually vote for their favorites. Points are awarded based on the number of votes an idea receives. It’s a structured, engaging way to share knowledge and ideas in a virtual or in-person setting.
It is quite common to have participants suggest either similar ideas or ideas that belong together or relate to each other, so we added the possibility for the kahoot host to drag idea cards on top of each other to logically group them into a stack.
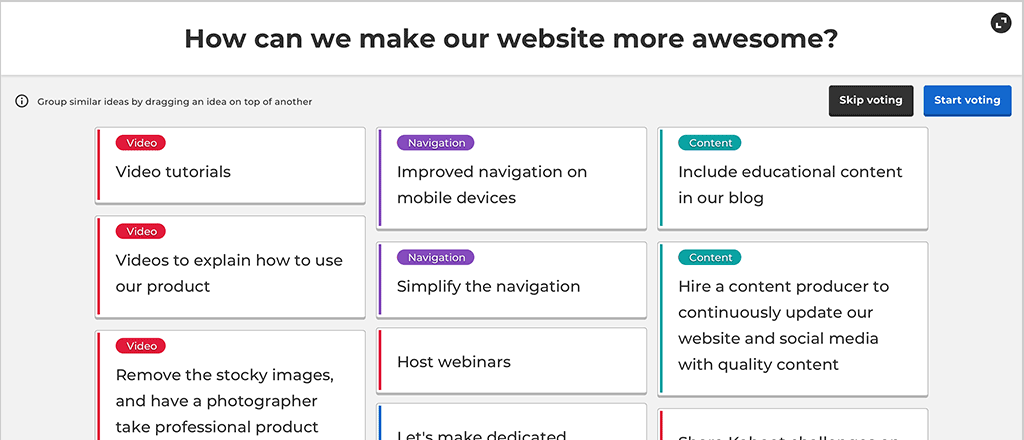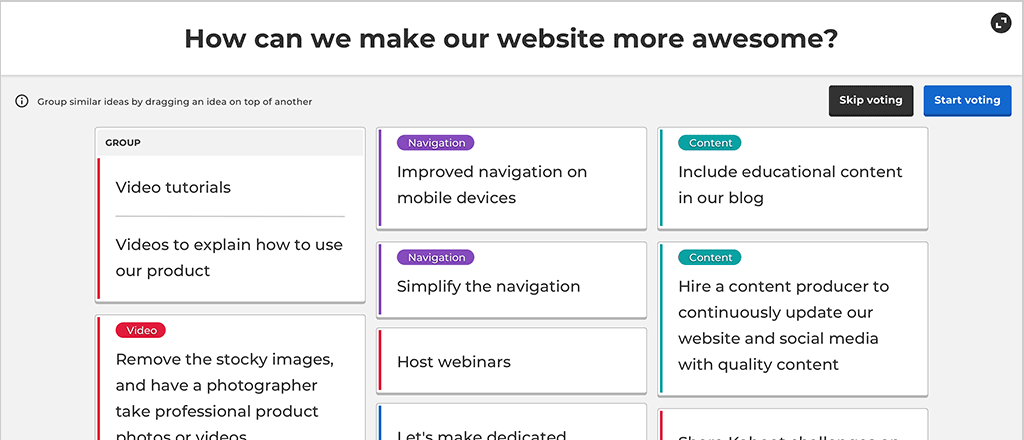
Animated illustration of the Brainstorm question grouping
Clustering
We explored a few design ideas around the concept of grouping. For games with a lot of participants, we thought it would be slow and cumbersome for the host to sort all the participant suggestions, for several reasons. Many of those suggestions would inevitably be equivalent or very similar. For a brainstorm question about outdoor activities, participants could submit text such as “hiking”, “hike”, “let’s go on a hike”, “taking a walk in the forest”, etc. The host would need to group all those suggestion cards into a single stack. For a large enough number of participants, this grouping activity could become long and tedious.
I had some previous experience with clustering of news articles, so I suggested we could test machine learning, and in particular unsupervised clustering, to have the system automatically propose groups of user suggestions based on similarity of meaning.
The approach I had used previously relied on common keywords in news article titles to identify texts about the same topics. Such a solution would be inadequate in this case, where user submitted texts would often consist of 2-3 words or less.
In addition to this short text problem, we would need to provide a good clustering suggestion for short texts in multiple languages. At the time, our platform was not yet localized, but we certainly had users creating kahoots and submitting text content in many different languages.
To summarize, the requirements that our clustering solution would need to fulfill were:
- Short texts, even just 2-3 words
- Support for at least our core languages, such as Spanish, Portuguese, German, French, Dutch and Norwegian.
- Cluster hundreds of suggestions within 5 seconds
Clustering with a slight twist
There are commonly used solutions to unsupervised clustering of text. Some, as mentioned, revolve around Jaccard similarity, or term frequency of tokens in documents. In more recent years, techniques like word2vec demonstrated that word embeddings could lead to significantly better clustering accuracy.
An embedding is a way to transform words in a document into a list of numbers, or a vector. If the vector is two or three dimensional, it’s easy to think about a word being placed in a 2D or 3D space, where words with similar meaning would be close to each other in this “vector space”.
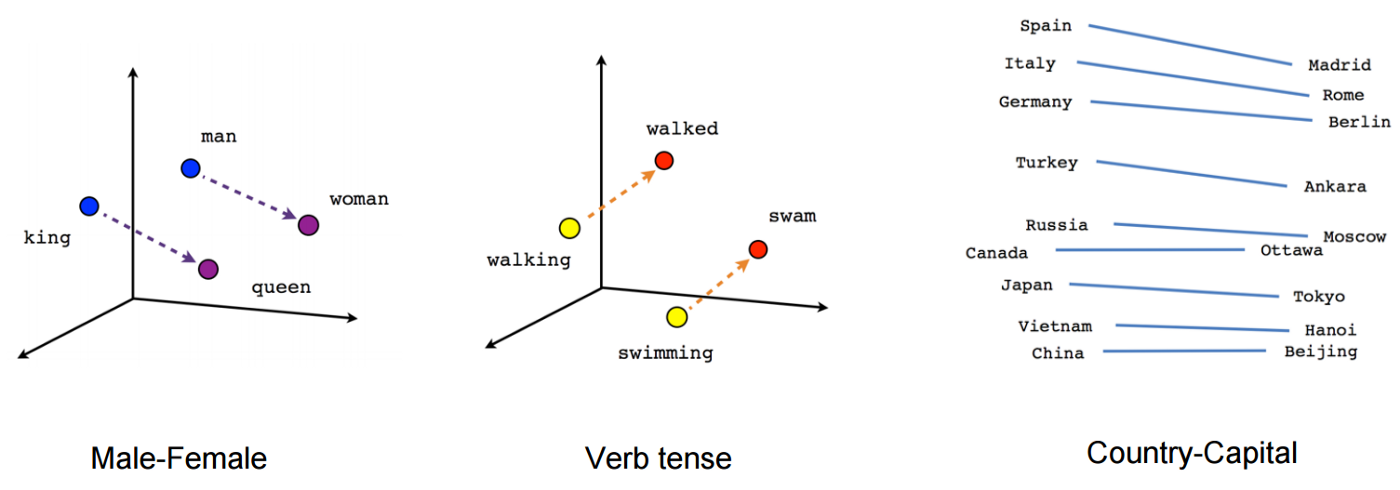
Vector space model example image by Hunter Heidenreich (https://towardsdatascience.com/introduction-to-word-embeddings-4cf857b12edc)
In practice, embedding vector spaces can have even 1,000 dimensions, so that’s harder to wrap our minds around. Luckily, computers can deal with this complexity.
SentenceTransformers
A lot has happened in NLP since word2vec. Introduced in late 2017, the Transformer class of deep learning language models have since been improved and popularized. The main purpose of a Transformer deep neural network is to predict the words that follow the given input text. A Transformers network is composed of two parts:
- an encoder network that transforms the input into embeddings
- a decoder network that given the embeddings, generates the text predictions.
The encoder part of a Transformer network plays a similar role to what word2vec used to do. Given a sequence of words, it produces a list of n-dimensional vectors that represent each word. In most common use cases, a single vector for a sentence is what we’re after. One way to implement this is to take the average vector of all the component words. Regardless of the actual details, there needs to be some way of combining the individual word vectors into a sentence-level vector.
Many open-source libraries provide this functionality out of the box, giving us easy access to the latest transformer-based deep learning language models. The library I used for this project was the excellent SentenceTransformers.
The key insight is that it’s possible, and in fact quite effective, to run a classic clustering algorithm, such as k-means on the embedding vectors computed by a Transformer model of the initial documents input. A quick prototype we built in the initial exploration phase proved to be extremely promising!
Model selection
The SentenceTransformers library provides access to several language models out of the box. Choosing an appropriate model is critical to achieving good accuracy in the task at hand. Some of the available models have been tuned specifically to get better performance when used in semantic textual similarity and thus clustering.
At the time we built this — October 2020 — the best performing model for semantic similarity embeddings that had multi-language capability was xlm-r-bert-base-nli-stsb-mean-tokens. . However, new and better models are being constantly developed. We will be soon evaluating the new models for use in our production deployment.
Problems of this approach
Clustering with the k-means algorithm is simple and effective, it’s performant and it scales well to thousands of data points. For our task, it presents a problem though: the number of desired output groups or clusters has to be known before performing the clustering process.
In our case, we don’t know how many clusters we will have in the end. It all depends on the individual users’ inputs. How to solve this problem then?
Initially we tried to use simple heuristics to estimate the number of clusters given the number of input sentences, but it was immediately clear that any heuristics we used proved to be ineffective. It’s simply not possible to predict the number of final clusters.
Luckily, I found an excellent article by Jessica Temporal on the elbow method.
Estimate the number of clusters: the elbow method
A reasonably effective way to estimate the optimal number of clusters is the elbow method. The method consists in performing the clustering for a range of possible output cluster numbers, and picking the solution that minimizes the cluster’s inertia, a measure of the cluster internal coherence. In other words, applying the elbow method means you need to perform the clustering many times over and choose the number of output clusters that optimizes the final result.
For example, if we need to cluster 20 user submitted ideas into groups, and we don’t know how many groups there will be, applying the elbow method means we need to perform the k-means clustering with the number of output clusters set to 1, then 2, then 3, then 4, and so on, up to a possible maximum of 20 clusters.
Unfortunately, this implies that the processing time for clustering will be much larger, increasing linearly with the number of attempts we need to run, and in the worst case, with the number of data points to be clustered. To speed things up, we can try to apply a few heuristics. We can exclude some edge cases. The case where all sentences would be clustered into one group is not so interesting and not probable either. It’s also unlikely that every single sentence would constitute a cluster of its own.
In the end, the optimizations we ended up applying are the following:
- Exclude the case of the number of resulting clusters being 1 and start with 2.
- Define a maximum number of iterations for the elbow method (in our case we chose 40) to avoid performing too many steps in case of large number of input sentences.
- In case the number of iterations would go over 40, skip some values and only sample some numbers of output clusters instead of all of them
- Stop iterating when the cluster coherence (quality) metric starts to decrease below 80% of the maximum value seen
Even with all those heuristics applied, the clustering of the transformer model embeddings proved to be too slow.
Dimensionality reduction
A common strategy in these cases is dimensionality reduction. The embedding vectors produced by the transformers model have 768 elements by default. When the number of input sentences is large, say 200 or more, the embeddings matrix is 200×768 elements, which is slow to process without dedicated GPUs. Currently, we are running this clustering model in Kubernetes, but sadly we haven’t yet found a good way to run GPU-enabled containers in our GKE clusters.
The scikit-learn library provides several methods for reducing dimensionality of matrices. I don’t know enough about these algorithms to explain them, but we tried a few, namely PCA and SVD and landed on the TruncatedSVD module for our needs. The result of these methods is a matrix with a lot less dimensions than the starting one. Magic!
I hope not to upset any data scientists out there, but dimensionality reduction was an extremely convenient mechanism to build an explicit quality vs performance tradeoff in our product. We implemented simple heuristics that select a target number of output dimensions given the size of the input dataset. If the input dataset size is greater than a certain threshold, we reduce the dimensions to 64 instead of 768. The larger the input dataset, the more we scale down the embedding dimensions, going to 16, 8, and even 4 for datasets larger than a few hundred sentences. The implication is that the clustering quality will suffer with very large datasets, and it is a conscious tradeoff we made to keep the API latency acceptable.
We’ve employed other lower-level tricks as well, of which I have written about in more detail in this article.
In the end, I believe we managed to achieve decent clustering quality for a large range of input datasets in a handful of seconds. We worked on other fronts as well, studying the user experience carefully. For example, by starting the clustering process a few seconds before the user submission deadline, we can effectively “hide” if the clustering API call is occasionally slower.
Further work and research
I find it mind-blowing that a project like this was prototyped in a few days and then implemented in a few weeks of work, even considering its limitations! The full implementation of the Brainstorm question of course was much longer, including all the complex frontend and backend infrastructure required.
The time available for the clustering part quickly came to an end, so we shipped the current implementation. Hopefully, we’ll be able to prioritize more improvements to it, and we have plenty of ideas for how to make it better, including:
- Review our choice of transformer model for the embedding computation. It’s been a while since we picked one, and several new state-of-the-art models have been developed and published.
- Evaluate the use of auto-encoders to “compress” embedding vectors. Clustering of high dimensional data with k-means is considered problematic. At the time, I thought that exploring auto-encoders usage would be unfeasible given the amount of time we had available.
- Try other clustering algorithms and tools in more depth. Among them, we had looked at HDBSCAN and FAISS. We tried HDBSCAN briefly, and it didn’t seem to perform very well, but more thorough analysis was needed.
This project is one of the most interesting I have ever worked on. I’d like to thank my team at Kahoot! for giving me the opportunity to give this a try and working with me to integrate this into the Brainstorm question functionality.
It’s been very exciting to see it come to light, and we had a lot of fun hand-picking examples where it either failed badly or it surprised us with a particularly clever clustering. I hope we’ll get to improve it even more in the future.
If you have suggestions for improvements or have feedback on this article, please get in touch! I would be delighted to hear from you. You should also consider joining us! Check out our open positions.
Further reading
Here’s a list of links that helped me along the way. I hope you may also find them interesting:
- A general introduction to text clustering
- A detailed article about word embeddings that also explains word2vec
- Scikit-learn decomposition algorithms page
- A helpful article about the elbow method and how to apply it
- The original post on the fast.ai forums that led me to the SentenceTransformers library to compute the sentence embeddings